Inefficiency and increased vulnerability due to visibility gaps in IT operations (ITOps) and security operations (SecOps) can leave IT teams constantly playing catch up. The BMC Helix AIOps release for BMC Connect 2024 aims to solve these challenges, all while improving the overall operator experience with BMC HelixGPT. Bringing together service management, observability, and vulnerability data, and using integrated workflows and automations to streamline incident response and risk management, BMC Helix enables teams to collaborate and resolve problems before they impact the business.
BMC Helix AIOps: Respond proactively to incidents and outages with a lot less effort
Proper use of artificial intelligence (AI), including causal, predictive, and generative AI (Gen AI) for smart assistance, can speed up incident resolutions and boost productivity. The latest release of BMC Helix AIOps enhances troubleshooting workflows and enriches the operator experience by introducing the BMC Ask HelixGPT virtual assistant, which helps IT operations teams get answers to common troubleshooting questions using predefined prompts. The log insights surfaced to DevOps and site reliability engineering (SRE) teams enable them to identify unusual behaviors in log data, without having to manually sift through thousands of log entries. The chat-mode interface makes it easy to get to the root cause faster, thereby reducing mean time to repair (MTTR). Altogether, the solution eliminates war-rooms by helping teams:
- Reduce manual investigation work with an AI assistant that retrieves answers to commonly asked questions during troubleshooting.
- Act rapidly by understanding impacts with topology, root cause isolation, situation explanation, and change risk prediction, all in a business context.
- Eliminate manual troubleshooting with logs and resolve incidents faster by identifying unusual behaviors in log data.
The addition of new, synthetic session data, Netreo events, and Stackify metrics allows BMC Helix AIOps to advise specific actions based on more complete data.
ServiceOps: Balance speed and risk in DevOps
For organizations practicing ServiceOps to balance speed and risk in service and operations management (ITSM/ITOM), the enhanced integration with ITSM systems allows BMC Helix AIOps to initiate workflows and create incident tickets from AIOps-created situations, thereby reducing incident noise and costs. The integrated ITSM and AIOps workflows streamline incident management and eliminate context switching by cross-launching between BMC Helix AIOps and ITSM systems from BMC and ServiceNow.
The most effective way to manage change and its impact is to proactively analyze risks to avoid making changes that are likely to cause an incident. The current change management process typically involves manual analysis of risk and lacks real-time operational data for accurate risk predictions. The new Gen AI-powered change risk advisor in BMC Helix AIOps reduces change failures in complex systems by surfacing risky changes that help users analyze change requests that may impact the service. Using Ask BMC HelixGPT, DevOps and SRE teams can follow up with questions and get responses for a given change request so they can continue to deploy quickly and with confidence, only delaying their push when a potential failure is detected.
By journeying towards ServiceOps, IT teams will:
- De-risk DevOps by catching unforeseen risks in real time and using BMC Ask HelixGPT to ask questions around a given change request.
- Prevent and identify risk changes with more precise risk and impact analysis of ITSM/ITOM data.
- Reduce incident noise and costs through integration with ITSM, allow BMC Helix AIOps to initiate workflows and create tickets from situations.
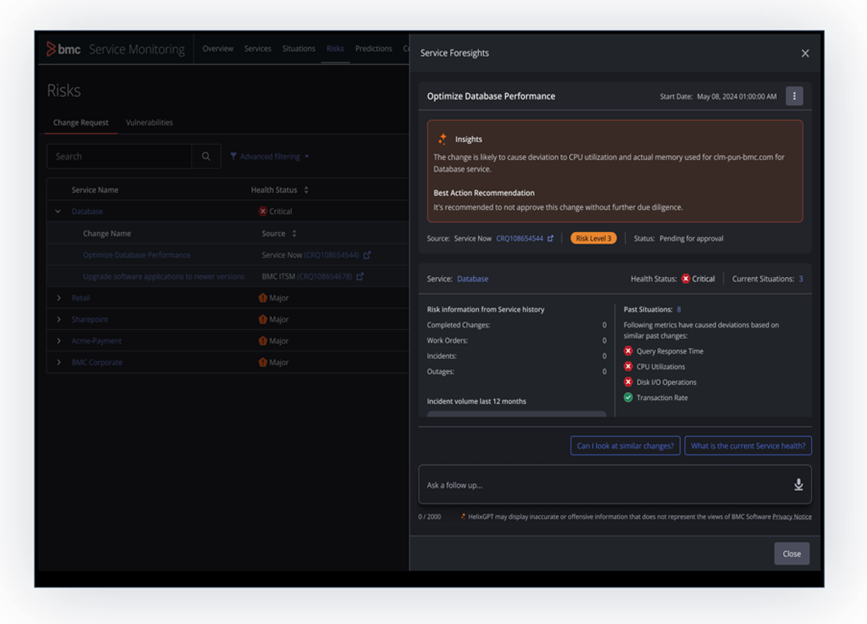
Figure 1. Gen AI-powered change risk advisor in BMC Helix AIOps.
VulnOps: Resolve exposures faster with risk and impact analysis
Automation is crucial to improving operational efficiency and driving faster vulnerability incident response. More and more vulnerabilities come out every day and operators are not fast enough to identify solutions for them. For ITOps and SecOps teams, new vulnerability scanning capabilities in BMC Helix AIOps enhance the visibility of risks with the context of the services impacted. With service vulnerability risk, organizations get protection through continuous scanning and monitoring of the organization’s assets and potential risks.
Vulnerability best action recommendation (VBAR), another key capability in BMC’s vulnerability operations (VulnOps) solutions, uses BMC HelixGPT to reduce the noise in vulnerability management and accelerate automated responses with code generation, so ITOps and SecOps teams can meet regulatory compliance and internal policies and procedures. With these combined capabilities, organizations can:
- Focus on the severe vulnerabilities through visibility into services and owners with the highest level of vulnerability risks.
- Speed vulnerability remediation by identifying the required patch or potential workaround for each vulnerability using AI-powered VBAR.
- Reduce noise in vulnerability management and prioritize the real risks so teams know what, where, and how to fix the issue.
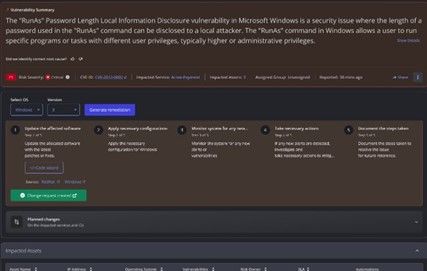
Figure 2. Gen-AI powered VBAR in BMC Helix AIOps.
BMC Helix Discovery: Gain visibility of complex networks, containers, and cloud resources
Enterprises deploy complex network topologies using various protocols. Border Gateway Protocol (BGP) is one of the most used protocols to build logical connectivity across network devices within and across datacenters. In the latest BMC Helix Discovery release, IT and networking teams can discover complex network topologies using BGP to gain comprehensive network visibility across their infrastructure to improve network troubleshooting and help BMC Helix AIOps provide holistic, accurate root cause correlation. Other BMC Helix Discovery enhancements include:
- Deep container discovery, which enables IT teams to understand the software running inside containers and the impact on services from outages within the cluster.
- Implicit discovery scanning in Microsoft Azure and Oracle Cloud Infrastructure (OCI), which uses existing cloud API scans and credentials to discover all components of running cloud servers.
Netreo: Accelerate network troubleshooting with improved efficiency
Since the BMC acquisition of Netreo and Stackify earlier this year, we’ve been busy with integration work to consolidate data for end-to-end visibility and AIOps. Customers using Netreo and Stackify will be able to ingest events and metric data into the BMC Helix platform through intelligent connectors. This data will be useful for unified monitoring and enabling AIOps use cases such as root cause analysis and incident resolution.
To accelerate network troubleshooting, Netreo Path Insights turns every possible connection route into a visual histogram backed with deep performance statistics. This capability reduces MTTR by enabling IT teams to quickly track and resolve remote performance issues with color-coded network mapping and an intuitive user interface.
Additional enhancements
Other new enhancements include advanced reporting with BMC Helix Dashboards in BMC Helix Continuous Optimization, which simplifies reporting and auditing for capacity management by providing the ability to manage basic and advanced reports in one place. IT teams can schedule, distribute, and archive reports with proper access control.
We’re continuing to optimize how ITOps and SecOps teams interact with our AIOps solution. Whether through integrated workflows, intelligent integrations, deep network and container discovery, or security vulnerability automation, each update aims to improve IT and security operational visibility and efficiency. To learn more about the BMC Ask HelixGPT virtual assistant, change risk advisor or our VulnOps solution, contact us for a consultation.
]]>AIOps vs. observability dilemma: which one is better?
The term observability has been around for over 10 years, but in the last three to four years, the concept has caught fire, albeit without sufficient guidance. That has led to tool sprawl, and now, in large enterprises, it is not uncommon to have 15 to 20 observability tools (and yes, even the old-style monitoring tools have been rebranded to observability, too). There are too many signals for IT to sift through, and they’re overwhelming IT teams across large enterprises. How do you make sense of all these signals when you’re dealing with a major incident?
For IT leaders, applying the appropriate technology to the task at hand becomes imperative when dealing with all the noise, complexity, rapid changes, and fast-paced innovation. When it comes to AIOps and observability, which approach makes the most sense for your business—or do you even have to choose?
Not necessarily, if you implement the right AIOps solutions in your environment. Here, I will explore the two approaches to help you determine whether AIOps or observability will help you achieve your IT operations (ITOps) and business goals. To dive deeper, check out our AIOps Is Not Observability whitepaper or the video interview with Carlos Casanova, a principal analyst at Forrester, below.
AIOps and Observability Defined
Artificial intelligence for IT operations, or AIOps, uses AI and machine learning (ML) to automate IT Ops, from reconciling and analyzing data collected by various sources—including observability tools—to conducting root cause analysis and automated remediations. AIOps is a prescriptive and proactive means to direct IT teams to the source of problems with high confidence and context, ultimately reducing or eliminating the time spent troubleshooting an issue.
AIOps can take in volumes of data (from observability tools or natively), reconcile and normalize it, and provide a unified view (east-west) across IT domains—proactively pointing IT to the source of problems and often preventing an incident from becoming a business-impacting problem. AIOps focuses on automatic problem resolution when problems do occur and preventing emerging potential incidents from happening.
On the other hand, observability tools also collect massive amounts of data to help IT teams infer the state of their observable systems. With this data, IT practitioners can query the data to iteratively troubleshoot and build awareness of the systems’ state from the data. Observability can be critical to gain insights into the performance of distributed systems, and often requires knowledge of query languages (such as PromQL, or others) to quickly interrogate all the collected data.
Key differences
The differences between AIOps and observability can be boiled down to the following:
- AIOps reconciles ingested data and delivers a unified view (east-west) across disparate tools and domains versus observability tools being used to explore data after a problem occurs and within the observability domain (north-south), often isolated from other observability domains.
- AIOps focuses on automatic problem resolution and preventing incidents from happening versus observability tools, which enable data exploration
- AIOps provides noise reduction and root cause analysis versus observability data, which is used for interactive exploration
- AIOps focuses on automation and intelligent remediation using AI/ML versus observability, which focuses on data collection and investigation.
- AIOps uses predictive algorithms to optimize service assurance versus observability, which uses capacity planning purposes in semi-automated ways.
- AIOps systems provide best action recommendations based on the past and in real-time, ML-driven insights versus observability, which provides explorative iteration.
How AIOps Drives Value for IT
Enterprise IT organizations today are already seeing the gains of applying AIOps across their environments using BMC solutions.
BMC’s AIOps is powered by its composite AI, including causal, predictive, and generative AI (BMC HelixGPT) solutions, which automate traditional incident analysis and offers a clear, plain-language summary of the problem—along with information on how the same type of problems was solved in the past.
Using composite AI, an AIOps solution can detect an anomaly, generate a summary of the incident, and suggest a best action recommendation (BAR). Automated incident resolution with AI and generative AI (Gen AI) prevents downtime and allows IT to perform health checks preemptively, improving overall system reliability and resilience.
AIOps can also accelerate troubleshooting workflows by providing predefined prompts to answer questions that lead to better understanding of complex systems, and ultimately, faster resolution. Using a solution such as Ask BMC HelixGPT speeds up the process and results in quicker resolutions.
Gen AI in AIOps solutions such as BMC Helix helps IT teams confidently conduct changes, mitigating the risk that a change will negatively impact the environment. Our AIOps approach, coupled with ServiceOps, enables flexible change risk management and automated or hybrid change governance.
AIOps can also use its knowledge of historical usage patterns and business trends to accurately predict future resource demands. This helps prevent outages and optimizes operations by allowing enterprise IT to run what-if scenarios to right-size capacities for user demands. In this scenario, AIOps helps organizations proactively plan for capacity, ensuring both performance and cost efficiency.
AIOps Drives Value for Observability
IT teams could achieve greater benefits from aggregating observability data into their AIOps solution. AIOps delivers true value for observability and helps enhance this understanding with AI/ML-driven automation and predictive and proactive (preemptive) capabilities, allowing IT and the business to make informed decisions. AIOps enables IT teams to scale and be more productive and support a much greater number of complex systems.
Observability tools provide an abundance of signals to IT teams, and AIOps synthesizes those signals to determine a root cause and provide a BAR based on ML. Observability is important for gaining insight into the performance of distributed systems, while AIOps helps enterprises achieve better business outcomes through intelligent operations and context.
As observability data becomes more critical across highly distributed, sophisticated environments, AIOps steps in to make sense of the noise, pinpoint the problems or prevent them, and enable IT to improve service reliability and deliver exceptional user experiences.
To summarize: AIOps is not observability, AIOps drives value for observability. So, which one is better? That depends on the outcomes you want to achieve.
Learn more in white paper that digs deeper into AIOps and observability here.
]]>Historically, resolving complex service performance issues required IT teams to have years of experience. However, during an incident or an outage, it may be hard for these teams to find information about the systems or infrastructure, or know which actions to take to resolve problems. With the ever-growing complexity of IT environments, IT teams require a new level of efficiency to find the root cause and resolve issues. The latest BMC Helix ITOM 24.3 release accelerates the troubleshooting and resolutions workflows, all while improving efficiency, service levels, and the overall IT operator experience, with three new enhancements.
- BMC Ask HelixGPT Virtual Assistant: Improve troubleshooting workflows and the site reliability engineer (SRE) experience.
- BMC Helix Discovery-to-Dynamic Service Model (DSM) Sync: Unify discovered data for hybrid deployments and enabling business continuity.
- BMC Helix Discovery: Boost IT efficiency with new automations and enable quicker time to value with automatic Kubernetes discovery in the public cloud.
BMC Ask HelixGPT Virtual Assistant
In The Forrester Wave™: Process-Centric AI For IT Operations (AIOps), Q2 2023, BMC Helix was named a leader in the industry, acknowledged for our commitment to disruption, ability to empower DevOps, SRE, and network operations center (NOC) teams to detect and respond effectively, as well as the enhancements that continuously detect the state of infrastructure and recommend actions. The latest release builds on our leading automated remediation capabilities with the introduction of Ask HelixGPT Virtual Assistant to improve workflow efficiency.
One challenge that DevOps, SRE, and NOC teams encounter is the inability to identify the main cause and apply better actions, leading to difficulty in addressing incidents promptly. The Ask HelixGPT Virtual Assistant accelerates the troubleshooting workflow by providing predefined prompts to answer questions that lead to better understanding of complex systems and faster remediation.
- Get to the source of problems faster by asking questions in context of the situation.
- Eliminate manual troubleshooting and correlation of observability signals and change events.
- Gain a deeper understanding of your complex systems and apply better actions.
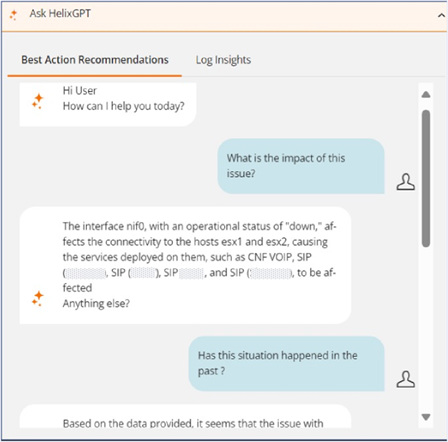
Figure 1. Ask HelixGPT Virtual Agent.
BMC Helix Discovery-to-DSM Sync
Synchronizing discovery data across on-premises and cloud environments brings a wealth of benefits to IT organizations by removing data silos, improving IT asset and service visibility, and empowering IT teams to resolve issues faster. This release introduces the capability to synchronize inferred discovery data (IDD) from an on-premises BMC Helix Discovery instance to another, whether in SaaS or on-premises environments, allowing organizations to use relevant data in the cloud while maintaining control of sensitive data in on-premises environments. This empowers IT teams to meet data security and regulatory compliance requirements while satisfying the operational needs of the business.
With the new BMC Helix Discovery-to-DSM Sync, on-premises BMC Helix Discovery data can now be used by the BMC Helix platform to enhance AIOps and observability. The new IDD sync also allows syncing of inferred hosts, software, network infrastructure, and storage devices, etc., and relationships from one BMC Helix Discovery instance to another. IT teams have the flexibility to use BMC Helix Discovery in their existing IT infrastructure with minimal operational interruption.
The new IDD sync also provides an efficient on-premises data consolidation option when raw directly discovered data (DDD) is not required. For IT practitioners who need to unify discovered data across multiple on-premises BMC Helix Discovery appliances for improved visibility and business continuity, this new capability is a great solution.
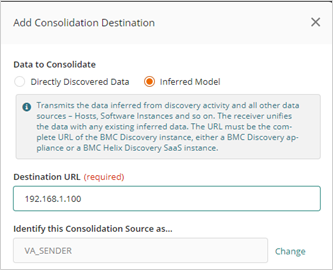
Figure 2. BMC Helix Discovery-to-DSM Sync
BMC Helix Discovery
Automation is crucial to improving operational efficiency. New BMC Helix Discovery enhancements focus on providing immediate value out of the box with automations and a better user experience for both our SaaS and on-premises customers.
Reduce manual management with BMC Helix Discovery management APIs
BMC Helix Discovery management APIs help IT teams automate the administrative setup and ongoing management of the on-premises BMC Helix Discovery deployment, thereby reducing manual maintenance. With the upgrade API, IT teams can perform an upgrade through an API process instead of manually. The register outposts API lets IT administrators automatically register the BMC Helix Discovery outpost with the BMC Helix Discovery service. Other REST APIs for making administrative changes and getting status updates include:
- Adding and removing BMC Helix Discovery users
- Adding and removing BMC Helix Discovery user groups
- Setting baseline settings
- Viewing the status of SMTP settings
- Viewing the status of LDAP settings
- Viewing the status of BMC Helix Discovery proxy pools
- View the status of BMC Helix Discovery clusters
Remove operational toil with automatic Kubernetes discovery in public cloud
Currently, customers who have deployed multiple Kubernetes deployments in the public cloud face operational toil in managing and maintaining the credentials of individual clusters, which is a pre-requisite for BMC Helix Discovery to discover the Kubernetes clusters and their mapping. Moving forward, this operational pain point is removed.
The current method BMC Helix Discovery uses to discover Kubernetes clusters requires a separate Kubernetes scan from the schedule scan for cloud. So, when BMC Helix Discovery finds Kubernetes clusters in an organization’s cloud during a cloud scan, a separate Kubernetes scan (with a separate credential to access each cluster) would need to be scheduled. If an organization has hundreds or thousands of clusters, this is inefficient and very time-consuming.
The new cloud Kubernetes BMC Helix Discovery capability allows BMC Helix Discovery to discover Kubernetes deployments without configuring and managing credentials for every Kubernetes cluster. The IT team would only need to run the cloud scan, which will find the Kubernetes clusters and then automatically start scanning the clusters to understand which containers are there and perform a deep dive as part of the cloud scan.
This capability uses the cloud API credential to enable automatic scanning of Kubernetes clusters. The only setup the IT team would need to do is give that cloud API credential additional access for BMC Helix Discovery.
By bringing the capabilities of cloud and Kubernetes scanning together, BMC Helix Discovery improves efficiency and removes the operational overhead of deploying credentials for every cluster.
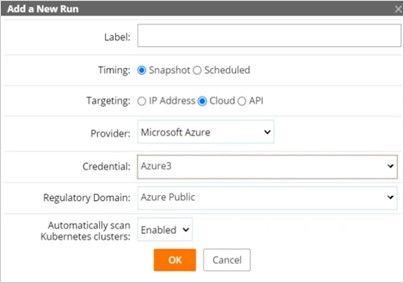
Figure 3. Cloud Kubernetes discovery using existing cloud credentials.
Improve visibility with BMC Helix Discovery Technology Knowledge Updates (TKU)
Expanded BMC Helix Discovery Technology Knowledge Updates (TKU) include new cloud (Microsoft Azure), Kubernetes, software, storage (NetApp and Dell EMC), and network (Cisco Meraki, Fortigate Firewalls, SNMP device definitions) coverage that improves visibility into the IT landscape. For the full list, see our documentation.
Other new enhancements include intelligent collectors for Netreo to further consolidate events for end-to-end visibility from application to infrastructure and network.
We’re continuing to optimize how IT teams interact with our observability and AIOps solution. Whether through REST APIs, intelligent integration, or data synchronization, each update aims to improve IT operational efficiency and observability. Stay tuned for more innovative features to come. To learn more about the BMC Ask HelixGPT Virtual Assistant, contact us for a consultation.
]]>A recent survey reports that 65 percent respondents say that their organizations are regularly using generative artificial intelligence (AI), and predicting it will lead to a disruptive change in their industries. AI has been curating content in the shadows and providing suggestions for decades; examples include everyday systems like search engines and media streaming applications. It wasn’t until early 2023 with the introduction of ChatGPT that AI became mainstream, bringing a conversational experience where AI responds instantaneously and generates contextual and human-like response on any topic to our fingertips. This is having a disruptive impact at all levels, from learning in classrooms to investment decisions in corporate boardrooms.
R&D investments in generative AI accelerated in the last year, uncovering new and compelling uses cases for IT operations (ITOps). According to IDC research spending on generative AI will jump from $16 billion this year to $143 billion in four years.
In this blog, I want to focus on generative AI use cases along with intelligent automation recommendations that make ITOps more efficient and cost-effective. Generative AI-based learning and the resulting conversational experience is transforming how IT uses actionable and contextual insights from their operations and service management data. However, generative AI-based outcomes in addition to inputs from telemetry, ticket, and knowledgebase data also require domain-specific context to respond with a high level of confidence.
Figure 1 below summarizes how observability and service management converge across a composite (predictive, causal, and generative) AI pipeline to solve complex IT problems. The dynamic service model acts as input (domain-specific context) to the pipeline and carries context forward to aid in noise reduction, root cause analysis, and intelligent recommendations. The context helps put a boundary around the problem and impacted assets, so the AI algorithms predict and generate accurate responses.
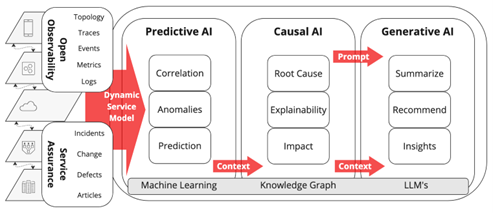
Figure 1: Composite AI with predictive, causal, and generative AI
Some history
The need for AIOps arose in the early 2000s for organizations struggling with maintaining an acceptable customer experience when dealing with a large, complex infrastructure. This resulted in a need for intelligent systems and automation to reduce mean time to repair (MTTR) or better predict or eliminate customer impacting outages.
AIOps solutions in early 2010 used AI and machine learning (ML) algorithms for anomaly detection and event correlation. These solutions applied predictive AI techniques and were effective in finding outliers and reducing event noise, but they proved hard to operationalize in large, complex environments. The biggest gap was their inability to encapsulate assets in a service model and perform contextual root cause isolation. This gap was difficult to fill for these early AIOps solutions as it not only required a connected and reconciled topology from the cloud to mainframe and application to network, but also a bidirectional integration with service management solutions to reduce service outages related to change.
Input to the AI for domain context
Data is the foundation of AI. The context of the input data is even more important to explain a problem or situation in completeness and high accuracy.
Dynamic service model
The dynamic service model is the foundational building block of a business service. It provides the domain-specific knowledge as input to the AI pipeline; this helps build cause-and-effect relationships and weed out nonsense correlations and hallucinations. This knowledge helps with contextual noise reduction, root cause isolation, and generative AI insights and recommendations.
The service model represents an end-to-end service view represented by configuration items (CIs) and their relationships, the model is automatically built and dynamically maintained. Figure 2 below shows an example for a dynamic service model, depicting a service spanning a distributed, hybrid, multi-cloud landscape connecting topology from the cloud to the mainframe and application to the network. The reconciled topology comes from discovery and monitoring tools for the application, infrastructure, and network. This service model breaks down organizational silos and is commonly used for:
- Noise reduction, root cause isolation, and change-impact monitoring in ITOps.
- Incident, change, and asset management in service management.
- Bidirectional incident, change, and root cause correlation and automation in a new ServiceOps approach that bridges service management and operations
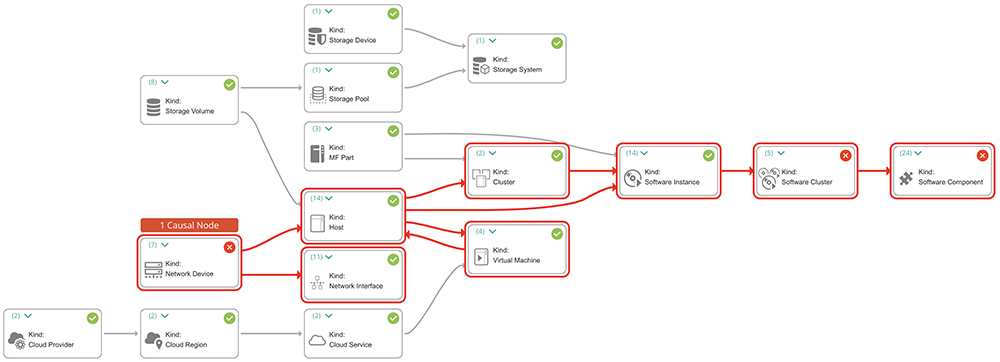
Figure 2. Dynamic service model for a distributed, hybrid, multi-cloud business service
Composite AI pipeline—Derive insights for intelligent automation
The dynamic service model provides contextual input to the composite AI pipeline. The pipeline applies predictive, causal, and generative AI techniques to help predict service disruptions, determine the root cause to expedite the triage process, and derive insights to recommend best actions to automate with confidence.
Predictive AI
Predictive AI is used to learn from historical metric trends to predict future impact. Correlation-based algorithms are also used to uncover relationships in data and see common trends and patterns to help with noise reduction and proactive problem analysis.
A prediction-based methodology approach predicts service level agreement (SLA) breaches and can detect abnormalities in telemetry data. SLA breaches impact service key performance indicators (KPIs) and impact critical business services. Proactively detecting and fixing potential service or end-user impact helps prevent service disruptions, resulting in improving customer experience.
Anomaly detection is also used to alert unusual patterns in the data that violate the normal baseline. Observability data inundates the systems with a high volume of telemetry data, making it very difficult to assess and set manual thresholds. Prediction-based anomaly detection eliminates the need to set manual metric thresholds and will find outliers.
Event, ticket, and log data correlation is becoming more important for predicting trends and uncovering underlying causes. Correlation also helps with noise reduction by clustering data based on natural language processing (NLP) algorithms and correlating insights with service impact.
Causal AI
Causal AI is used to determine root cause, and this would not be possible without the domain context that comes from the dynamic service model. The dynamic service model in Figure 2 shows how an impacted network device labeled as the “causal node” is impacting the upstream application.
When production issues unfold, observability events are mapped as cause-and-effect relationships across the dimensions of time and topology. This results in a graph depicting a causal chain of events as shown in Figure 3, with the impacted layers on the left, causal chain of observability events across time on the right, and root cause event in red. In this example, it is a network device.
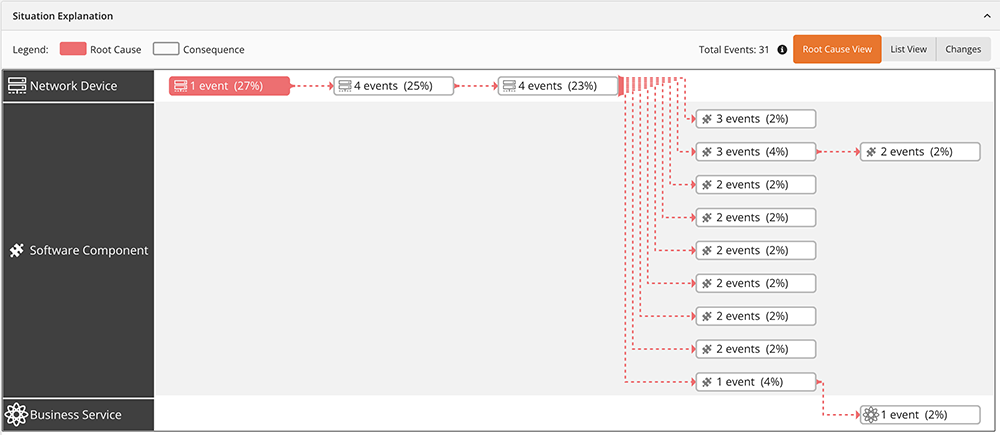
Figure 3: Causal graph of monitoring events and impacted layers
The causal graph is akin to a fingerprint and is stored in a knowledge graph for historical analysis. Causal AI helps to:
- Automate root cause CI isolation, eliminating the need for manual L1 triage or a war room scenario. The issue in this example is automatically assigned to the network subject matter expert (SME), reducing help desk fatigue.
- Correlate ITSM change requests to the root cause CI. If a rollback is required, the impactful change request is correlated with the root cause CI, henceforth ignoring the tens or hundreds of non-impactful change requests.
- Identify business service or end-user impact. A flapping switch is only interesting if the end user is, or is predicted to be, impacted. This helps prioritize and focus expensive engineering resources on impactful issues.
Generative AI
The dynamic service model, coupled with predictive and causal AI outputs, provides context for generative AI to execute the last mile and produce human-readable insights to improve service resiliency and avoid future disruptions.
Generative AI is used to train large language models (LLMs). The LLM comes pre-trained with domain knowledge on how to solve common operational issues and can optionally be further fine-tuned with customer data in a secure-tenant model to help improve the accuracy of the response.
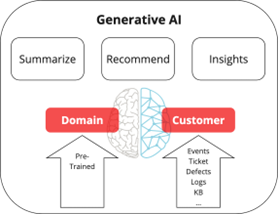
Figure 4: Generative AI uses pretrained domain and fine-tuned LLMs with customer data
The trained LLM can be relied upon to:
- Generate a human-readable problem summary of the ongoing issue based on the identified root cause, causal graph, and end-user impact to expedite the triage process and reduce MTTR.
- Recommend the automated best action to remediate based on past similar situations, tickets, defects, logs, and knowledgebase data to better avoid service disruptions.
- Converse and derive contextual insights from telemetry, incident, and change data, which helps break down silos and surface change-related risk and outages.
Path to self-remediation
The composite AI pipeline applies AI techniques to input necessary domain context, derive actionable insights from domain-specific contextual intelligence, and use enhanced decision-making to automate with confidence, as shown in Figure 5.
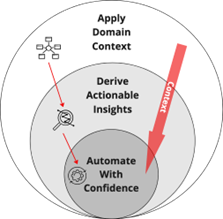
Figure 5: AI pipeline applying composite AI techniques to automate decision-making
The goal for operations team is to achieve zero-touch operations, where the AI detects, triages, and remediates with minimal human intervention. In my previous blog, I talked about the 7 core principles for AIOps to achieve zero-touch operations.
]]>IT operations and security are changing fast.
As technical architecture, requirements, and threats evolve, a wide range of new concepts and practices are emerging to meet them.
Unfortunately, these terms can be difficult to keep straight as many of these terms look and sound similar. In this blog, we will clear up any confusion around the most common of these terms, including AIOps, MLOps, DevOps, ITOps, and observability.
We will:
- Provide a high-level understanding of each term
- Highlight many of their differences
- Explore how they work together
Let’s get started.
AIOps explained
Artificial intelligence for IT operations (AIOps) uses AI to automate many IT operations. Specifically, AIOps focuses on automating the maintenance and management of IT infrastructure. This includes automating a wide range of tasks such as applying patches and updates, maintaining general IT hygiene, and investigating IT security and operational incidents.
Find out how BMC approaches AIOPs
MLOps explained
Machine learning for IT operations (MLOps) focuses on automating, simplifying, and streamlining ML models at every step of their lifecycle and improving workflows to develop, deploy, and manage them faster and easier. This includes standardizing processes, increasing visibility and collaboration, and automating DevOps tasks.
Get a deeper explanation of MLOps
DevOps explained
DevOps combines software development with IT operations (ITOps), integrating the two teams, their workflows, and their objectives into one process. It accelerates the software development process, increases collaboration, and ensures application quality. DevOps includes automating tasks and standardizing libraries, but mostly focuses on improving human practices.
Check out our DevOps tools
ITOps explained
ITOps is a broad term that includes the wide range of practices involved in managing IT infrastructure and services. It is a core function within IT that also touches every other function within the organization. It can include everything from provisioning laptops to deploying physical and virtual infrastructure to resolving IT support tickets.
Observability explained
Observability is the ability to know what’s going on within a piece of IT equipment, an application, a technical process, or anything else included within the IT stack. Observability is a property. An asset has observability (you can know its state) or it does not. It is required for everything from incident investigation to risk management to performance improvement.
Explore what true observability can do for your organization
Understanding the differences
Many of these terms are used interchangeably—even when they refer to fundamentally different processes, concerns, or functions. Let’s review some of the most confusing pairings, and what makes them different.
AIOps vs. MLOps
AIOps and MLOps are often confused. This is most likely because AIOps involves AI, and MLOps involves ML, and AI and ML are often seen as very similar, if not the same thing.
However, AIOps and MLOps refer to fundamentally different functions. AIOps refers to using AI and automation to streamline the management of IT infrastructure, while MLOps refers to using multiple practices to streamline and improve the management of ML pipelines.
AIOps vs. DevOps
Similar to AIOps vs. MLOps, AIOps and DevOps are different functions. AIOps focuses on managing the IT stack more efficiently and effectively, while DevOps focuses on improving software development processes.
There is some overlap. DevOps does include bringing ITOps into the software development lifecycle (SDLC), and it will touch certain components of AIOps. But overall, these are two separate practices areas with different processes and goals, and only a few shared teams and members.
ITOps vs. AIOps
ITOps and AIOps have a lot in common. They are both concerned with maintaining the organization’s IT infrastructure, and include many of the same teams, yet there is one key difference between them.
ITOps refers to the complete set of tasks involved in deploying, managing, and maintaining IT infrastructure, while AIOps refers to a small set of practices around automating many of these tasks. As such, you can think of AIOps as a subset of ITOps that falls under ITOps’ broader umbrella.
AIOps vs. observability
AIOps and observability are two different things, even though they do feed off each other in positive ways. AIOps maintains IT assets, while creating observability gives you visibility into the state of those assets.
These two practices go hand in hand. Observability ensures AIOps has the data it needs to accurately detect issues, investigate them, identify their root cause, and effectively resolve those issues. Creating an AIOps practice will also increase data collection, and thus improve observability.
MLOps vs. DevOps
MLOps and DevOps are separate, but related terms. DevOps refers to a wide range of practices involved in evolving the software development process, while MLOps only refers to improving ML pipelines.
However, MLOps and DevOps can be correlated in the same way that AIOps and ITOps can be correlated. MLOps can be seen as a subset of DevOps used when creating, deploying, and improving applications that include ML algorithms (which is effectively all software these days).
DataOps vs. MLOps
DataOps refers to the people, practices, and tools involved in managing the lifecycle of data. This includes everything from data generation to data collection and transformation to data monitoring and analysis.
MLOps and DataOps take a similar approach, but apply to different domains—MLOps to ML, DataOps to all things data. While DataOps will involve the data fed into ML models, it includes improving all data in the enterprise, and not just that used in ML.
ITOps vs. DevOps
ITOps is not directly related to DevOps. It includes everything related to managing all IT operations’ architecture and services within the full stack, while DevOps focuses on improving software development.
There is some overlap. DevOps combines some ITOps team members and assets with software development. And improving IT architecture and services within ITOps will improve DevOps processes and overall application performance. Yet these are two meaningfully different practices.
Telemetry vs. observability
Telemetry refers to either the process of collecting data from assets within the IT estate, or it can refer to the actual data itself. Observability refers to the ability to understand those assets because of the telemetry collected.
Observability primarily uses three forms of telemetry—logs, traces, and events. As such, there is no observability without telemetry. Yet an organization can collect a wide range of telemetry without stitching it together into a meaningful observability practice.
Data observability vs. data quality
Data observability is a subset of observability that focuses on revealing the known state of data and data pipelines within the IT stack. Data quality refers to the accuracy, completeness, and consistency of that data.
Data observability and data quality are closely related. An organization needs data observability to know whether or not they are collecting high-quality data. And if an issue is detected, data observability can show where in the pipeline data is being collected, transformed, or analyzed incorrectly.
APM vs. observability
Application performance monitoring (APM) refers to collecting performance data from applications, setting thresholds that determine whether the application is performant, and sending alerts when those thresholds are crossed.
APM and observability are often mistaken. APM is an action taken when an organization needs to check simple, static performance rules for an application, while observability allows a deeper, broader, and more holistic investigation that goes beyond known performance standards and issues.
Bringing them all together
Ultimately, while these terms refer to different practices and functions, they all have one thing in common—they are all required to develop, deploy, and manage technology in the modern enterprise. And because the modern IT stack touches every corner of the business, these terms often interconnect and depend on each other in surprising ways.
- AIOps makes DevOps easier and saves time for developers who no longer need to worry about managing the IT infrastructure they touch.
- AIOps is becoming a bigger and bigger part of ITOps as more core functions of maintaining IT infrastructure can be automated via AI.
- AIOps and observability are closely connected, to the point that some platforms are starting to integrate both into a single solution.
- MLOps applies DevOps principles to ML algorithms, and is increasingly important within all software development.
- DataOps brings DevOps principles to the development, management, and continuous improvement of data pipelines.
The list goes on. Every organization is eliminating its siloes, increasing collaboration between systems and teams, and creating a more holistic IT and business ecosystem.
In sum: Knowing how to put all these practices to work—in a manner where they interconnect and don’t compete—is now a critical component for every modern technology leader.
]]>To aid with our understanding of observability vs monitoring let’s look at the evolution of the enterprise IT world. Enterprise IT, application, and business service development are increasingly complex. The interdependencies within the underlying architecture have become more fragmented, resulting in difficulty visualizing the full IT stack.
The internet delivers IT infrastructure services from hyperscale data centers at distant geographic locations. Companies are moving towards cloud-native delivery, resulting in modern distributed applications and creating a perfect storm of complexity with constantly emerging technologies, hybrid-cloud infrastructures, and businesses expecting delivery of more features faster.
Companies are consuming these services—like microservices and containers—as distributed functions across layers of infrastructure and platform services. Consumers expect regular, continuous feature improvements through new releases.
To meet these requirements, IT service providers and enterprises must aggressively manage business service performance, improve stability, and predict and prevent performance degradation and outages—all in the context of the rapidly changing and evolving IT landscape. This requires closely observing and monitoring metrics and datasets related to service performance to optimize system availability, particularly during upgrades and code launches.
Observability seems like the hot new topic in the IT world, but the reality is it has been with us for a long time. Only recently, however, has it entered the IT realm, combining with monitoring to offer a more powerful approach to business service performance management. System observability and monitoring play critical roles in achieving system dependability—they may be interdependent, but they’re not the same thing. Let’s understand the differences between monitoring and observability, and how they are both critical for enhanced, end-to-end visibility.
What is monitoring?
In enterprise IT, monitoring is the process of instrumenting specific components of infrastructure and applications to collect data—usually metrics, events, logs, and traces—and interpreting that data against thresholds, known patterns, and error conditions to turn the data into meaningful and actionable insights.
Monitoring is focused on the external behavior of a system, specifically those data targeted for collection. Monitoring is most effective in relatively stable environments, where key performance data and normal versus abnormal behavior is known. When enterprise IT was predominantly run in an organization’s own data center, monitoring was an appropriate way to manage the environment.
The introduction of public and private clouds, the adoption of DevOps; the emergence of new technologies; the massive scale of data brought on by digital transformation; and the proliferation of mobile devices and IoT have created a situation where monitoring is no longer an effective approach for IT operations (ITOps).
Monitoring in IT systems focuses on overseeing the operation of servers, applications, and infrastructure to ensure they perform within expected parameters. It involves continuous surveillance of system metrics like network traffic, CPU utilization, and memory usage to detect performance anomalies or failures in real time. Effective monitoring provides alerts when metrics fall outside normal ranges, enabling IT teams to swiftly address and mitigate issues. This real-time crisis management is crucial for maintaining high availability and performance in enterprise environments.
Describing observability
The concept of observability was introduced by R. E. Kalman in 1960 in the context of control systems theory. In control systems theory, observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. In essence, it’s a method for learning about what you don’t know from what you do know. The relationship between the known and the unknown can be represented mathematically.
So, given the known state, external data, and enough time to do the mathematical calculations, the internal, unknown state of the system can be determined. This approach is well suited for modern, enterprise IT, as distributed infrastructure components operate through multiple abstraction layers. This makes it impractical and challenging to understand the health of complex services by selecting specific components to instrument for telemetry and looking for threshold breaches, events, etc.
The challenge to implementing observability in IT has been the volume, variety, and velocity of external data, combined with having the computational power and domain knowledge needed to analyze and make sense of it in real time. Effective ITOps teams now need observability platforms that can consume vast quantities of data from a variety of sources and submit that data to immediate intensive computational analysis. Fortunately, such platforms, like BMC Helix Operations Management, are now available.
Expanding on this, observability in IT extends beyond the basic functionalities of monitoring by providing deeper insights into the behavior of systems through comprehensive data analysis. It utilizes telemetry data including logs, metrics, and traces, which helps developers and operators not just see what is happening within the system, but also understand why it is happening. This depth of insight is crucial for troubleshooting complex systems, optimizing performance, and making informed decisions about future improvements in software architecture and deployment strategies.
Learn more about observability ›
What is the difference between observability and monitoring?
The main difference between observability and monitoring is that monitoring is better suited for simpler systems where parameters are well-known and performance is well-understood, while observability is better suited for more complex, multi-system environments with more potential unknowns.
For simple systems, traditional monitoring is effective and can provide some measure of insight into a system’s health. Consider a single server machine. It can be easily monitored using metrics and parameters such as hardware energy consumption, temperature, data transfer rates, and processing speed. These parameters are known to be highly correlated with the health of internal system components.
Now consider a large, complex business service. It is made up of multiple applications that span public and private clouds, a distributed infrastructure, and possibly a mainframe. There are too many systems, some not directly accessible, that if monitored without knowledge of the key performance data, systems, and error conditions, will generate too much uncontextualized data as well as unnecessary alerts, data, and false flags.
In the second case, an observability and AIOps approach is needed. Rather than selecting the data to monitor and examine the behavior of that data relative to trends, known errors, etc., all available data from all systems should be consumed. Aggregated into a high-performance data store, it should be combined with a comprehensive topology of all assets, systems, and applications that builds a comprehensive model of relationships and dependencies.
On this foundational observability layer, high-performance, domain-informed artificial intelligence and machine learning (AI/ML) algorithms can be applied to determine which externally observable data correlates with which services and infer the health of those services from their behavior. This is the power of an observability and AIOps approach, such as that used by BMC Helix Operations Management.
Find out how BMC Helix Operations Management can help you tackle challenging hybrid cloud environments ›
How do observability and monitoring impact business outcomes?
Observability and monitoring are not just technical exercises; they have profound impacts on business outcomes. By ensuring systems operate smoothly and are quickly repairable when issues arise, these practices directly contribute to maintaining high levels of customer satisfaction. For example, real-time monitoring of e-commerce platforms can detect and address performance bottlenecks during peak traffic, preventing potential sales losses and preserving customer loyalty.
Furthermore, observability provides businesses with actionable insights that go beyond problem-solving. It enables predictive maintenance, which can anticipate issues before they occur, thus minimizing downtime and its associated costs. This proactive approach saves money and enhances the overall customer experience by delivering consistent service quality.
Additionally, in environments where performance directly ties to revenue, like in financial trading platforms or real-time data services, observability’s role becomes critical. The ability to continuously analyze and interpret complex data streams ensures that performance stays within the threshold necessary for optimal operation, directly impacting profitability.
How have tech advancements shaped observability and monitoring?
The landscape of enterprise IT has undergone significant transformation, driven by advancements in technology that have reshaped observability and monitoring. The proliferation of cloud computing, for example, has expanded the complexity and scale of IT environments, making traditional monitoring tools insufficient for new dynamic infrastructures. Similarly, the rise of big data has introduced challenges in managing voluminous data flows as well as opportunities for deeper insights through observability tools.
These technological shifts have necessitated the development of more sophisticated tools and practices. AI/ML are now integral to modern observability platforms, enabling predictive analytics and automated problem resolution that were not possible with earlier systems. This evolution from reactive monitoring to proactive observability reflects a broader trend towards more agile and resilient IT operations.
Is observability used in DevOps?
The concept of observability is prominent in DevOps software development lifecycle (SDLC) methodologies. In earlier waterfall and agile frameworks, developers built new features and product lines while separate testing and operations teams tested for software dependability. This siloed approach meant that infrastructure operations and monitoring activities were beyond development’s scope. Projects were developed for success and not for failure: debuggability of the code was rarely a primary consideration.
Infrastructure dependencies and application semantics were not adequately understood by the developers. Therefore, apps and services were built with low inherent dependability. Monitoring failed to yield sufficient information about the known-unknowns, let alone the unknown-unknowns, of distributed infrastructure systems.
The prevalence of DevOps has transformed SDLC. Monitoring goals are no longer limited to collecting and processing log data, metrics, and distributed event traces; monitoring is now used to make the system more observable. The scope of observability therefore encompasses the development segment and is facilitated by people, processes, and technologies operating across the SDLC pipeline.
Collaboration among cross-functional Devs, ITOps, site reliability engineers (SREs), and quality assurance (QA) personnel is critical when designing a highly performant and resilient system. Communication and feedback between developers and operations teams is necessary to achieve observability targets of the system that will help QA yield correct and insightful monitoring during the testing phase. As a result, DevOps teams can test systems and solutions for true real-world performance. Continuous iteration based on performance feedback can further enhance the ability to identify potential issues in the systems before the impact reaches end users.
Observability offers actionable intelligence for optimizing performance, giving DevOps, SREs, and ITOps increased agility by staying ahead of any potential service degradation or outages. Observability is not only limited to technologies; it also covers the approach, organizational culture, and priorities in reaching appropriate observability targets, and hence, value-of-monitoring initiatives.
How does observability function in real-world scenarios?
Observability isn’t just theoretical; it has practical implications in real-world IT scenarios. For instance, consider a global e-commerce company that experiences sporadic system outages during high-traffic periods like Black Friday sales. By implementing an observability platform, the company can aggregate data across all system components—not just those predetermined as critical. This holistic data collection enables them to use advanced analytics to predict potential points of failure before they result in downtime, thereby not just reacting to system anomalies but also proactively managing system health.
Tools like dynamic baselining, anomaly detection, and automated root cause analysis play crucial roles in these observability platforms, supporting modern ITOps across complex and hybrid environments.
The evolution from traditional monitoring to sophisticated observability marks a significant shift towards proactive management of IT systems. By leveraging advanced tools like dynamic baselining, anomaly detection, and automated root cause analysis, businesses can both react to issues and anticipate them, ensuring higher system reliability and improved performance. Embracing these practices is essential for any enterprise aiming to thrive in the digital age, where agility and resilience are key.
]]>Today’s complex and dynamic architecture makes it increasingly difficult to trace an error back to the root cause of the problem. This results in slow incident response time, which can lead to service degradation and expensive downtime. We’re excited to announce new capabilities in the BMC Helix observability and AIOps solution portfolio that help teams improve service reliability and mean time to repair (MTTR) while streamlining incident management.
The BMC Helix ITOM 24.2 release introduces OpenTelemetry support for distributed tracing, BMC HelixGPT-powered log insights in the context of a situation, new service blueprints, and enhanced integration for correlation of incidents to situations. Other enhancements include expanded BMC Helix Discovery Technology Knowledge Updates (TKUs) and improved usability through advanced event filtering.
These key enhancements make cloud-native application data collection easier for IT operations and site reliability engineering (SRE) teams and reduce the time teams must spend manually troubleshooting problems or poring over complicated information.
Troubleshoot more efficiently with OpenTelemetry tracing
OpenTelemetry (OTel) is the open-source standard for instrumenting, generating, collecting, and exporting telemetry data to gain observability over microservices. Through the OTel collector, IT teams that include DevOps, IT operations (ITOps), SRE, and platform engineering, can get traces into BMC Helix ITOM, our observability and AIOps solution, without needing to use a third-party monitoring tool.
Our solution derives the rate, errors, and duration (RED) metrics from all the spans ingested to provide a highly accurate picture of an application’s behavior and give users a standardized starting point for troubleshooting microservices or any request-driven applications. By viewing a trace, you can track the complete flow of a request from one service to another and identify which part of the application is causing issues such as errors or latency concerns.
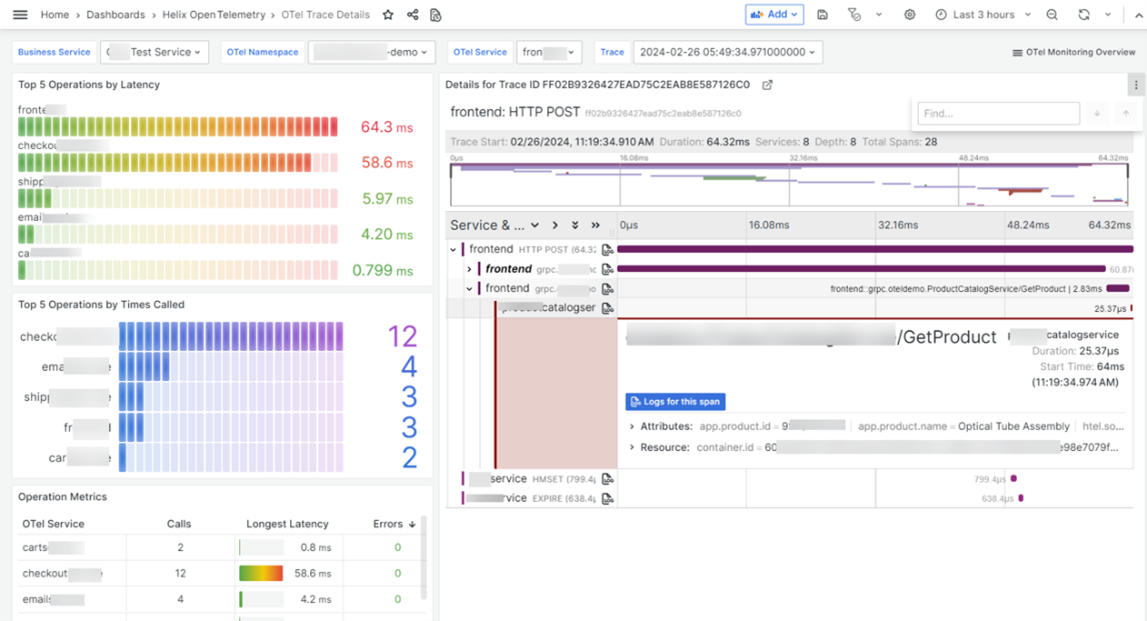
Figure 1. Visualizing a trace.
BMC Helix ITOM enriches OpenTelemetry trace data with a powerful topology mapping and visualization that gives IT teams a better understanding of the overall service and its dependencies and isolates root causes by correlating traces with topology, metrics, and events in the context of the problem. If an application issue occurs, you can identify the impacted application quickly. From that impacted node, you can launch the dashboard that shows the problem’s contextual RED metrics. Clicking on any error status will direct you to the relevant traces to pinpoint the issue.
In addition, the topology derived from those traces get reconciled and added to the solution’s network infrastructure topology mapping and visualization, giving IT teams end-to-end service visibility. This helps identify issues that stem from errors within the microservices or changes to the infrastructure or network.
Resolve incidents faster with AI-powered log insights
BMC Helix ITOM continues to invest in artificial intelligence and machine learning (AI/ML) capabilities to improve MTTR and team productivity. In January, we introduced the Best Action Recommendation (BAR) feature to help IT practitioners resolve issues and eliminate days of troubleshooting. Trained on past incidents, situations, and remediation actions, BAR uses generative AI to recommend potential solutions to resolve problems. IT administrators, network operations center (NOC) operators and SREs can use the “Ask BMC HelixGPT” tool to ask questions and get more details to questions such as, “What’s the impact of the issue?” and “Has this situation happened in the past?”
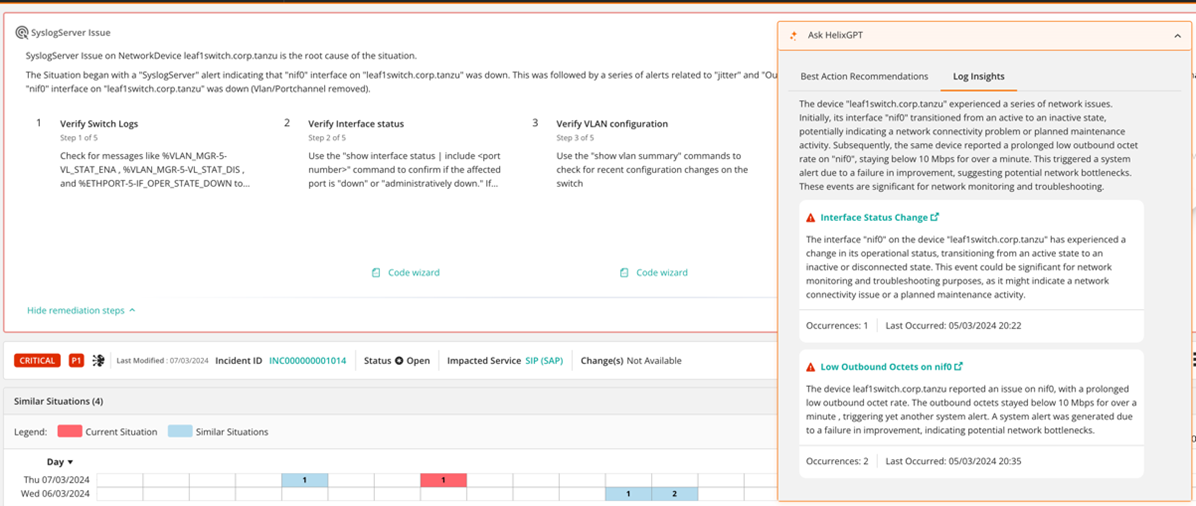
Figure 2. Log insights leveraging BMC HelixGPT.
Now, with log insights for situations, teams gain additional insights with important trends and patterns found in the context of the problem. Using generative AI for log data further enhances the functionality of BAR by reducing the noise and the time it takes to identify unusual behaviors in log data. Log insights provides a summary of the issue and a breakdown of the different occurrences so teams can make informed decisions with a clear explanation of the problem.
Automate incident management through a single interface
When you’re under pressure to respond to production incidents, nothing kills productivity more than context switching. The BMC Helix observability and AIOps solution portfolio eliminates context switching by enabling cross-launching between the situation view (where a generative AI-based summary and the root cause of the issue is shown) to your IT service management (ITSM) tool. By creating a single incident for many correlated events along with the impacted service and configuration item (CI) details, the solution significantly reduces the number of tickets created, as well as their corresponding costs and incident noise. ITSM and ITOps teams can now focus and collaborate more efficiently on solving critical issues.
Get better control of events
The new advanced event filter capability helps users view only the events they want to focus on to prioritize critical issues and diagnose them early by:
- Creating new filters and viewing events that match the specified priorities.
- Saving hundreds of filters and switching between them within the intuitive user interface (UI).
- Grouping devices and services based on technology, role, and geography.
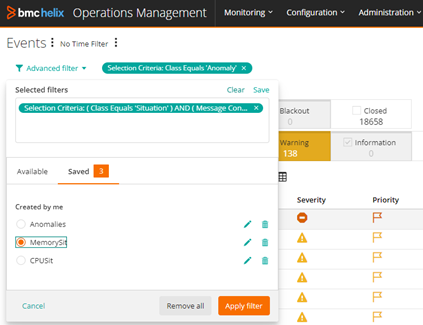
Figure 3. Advanced event filter in BMC Helix Operations Management.
Other enhancements
New service blueprints for service modeling
Speed the time to value (TTV) for customers creating service models with new out-of-the-box service blueprints for application performance monitoring, networks, cloud infrastructure, and mainframe that reduce contextual noise and enable root cause analysis.
New BMC Helix Discovery TKUs
Get expanded BMC Helix Discovery TKU content with new cloud, Kubernetes, storage, and network coverage that improves visibility into your IT environment. For the full list, see our documentation.
Want to see it working together? We’ll be happy to show you the latest features; request a demo today.
]]>In today’s continuously evolving IT environment, staying ahead sometimes means embracing both the tried and true and the cutting cutting-edge For organizations deeply invested in TrueSight Operations Management, the prospect of integrating advanced artificial intelligence (AI) capabilities might seem like a leap into the unknown. However, the future of operational excellence lies in blending existing strengths with the latest innovations. This is where BMC Helix AIOps and observability come into play, offering a bridge to the future. BMC Helix AIOPs is called as BMC Helix Service Monitoring Tile in the Helix Portal Landing Page.
I have had several inquiries regarding the feasibility of using existing TrueSight Operations Management and connecting it to the award-winning functionality of BMC Helix AIOps and observability. Customers are asking if they can adopt the latest BMC Helix AIOps and observability tools without replacing TrueSight Operations Management with BMC Helix Operations Management.
This blog previews the best practice steps and use cases for customers to connect TrueSight Operations Management to BMC Helix AIOps using BMC Helix Intelligent Integrations, and guidance to helpcustomers using TrueSight Operations Management who want to adopt both BMC Helix Operations Management and BMC Helix AIOps and observability to improve operational efficiency, reduce costs, and yield the benefits of a modern, highly available, cloud-native platform.
Working with available use cases
Use case 1— TrueSight Operations Management and BMC Helix Operations Management event data workflow using BMC Helix Intelligent Integrations
- Download, install, and configure the TrueSight Operations Management connector.
- Once the connection and integration are successful, send events to it.
- Through the connector, the events are propagated to BMC Helix Operations Management.
- As a next step, when we do any event operation like a closing event in TrueSight Operations Management, we will see the corresponding event closing in the BMC Helix Operations Management
- Please note there is no back propagation, as of now, of event status from BMC Helix Operations Management to TrueSight Operations Management.
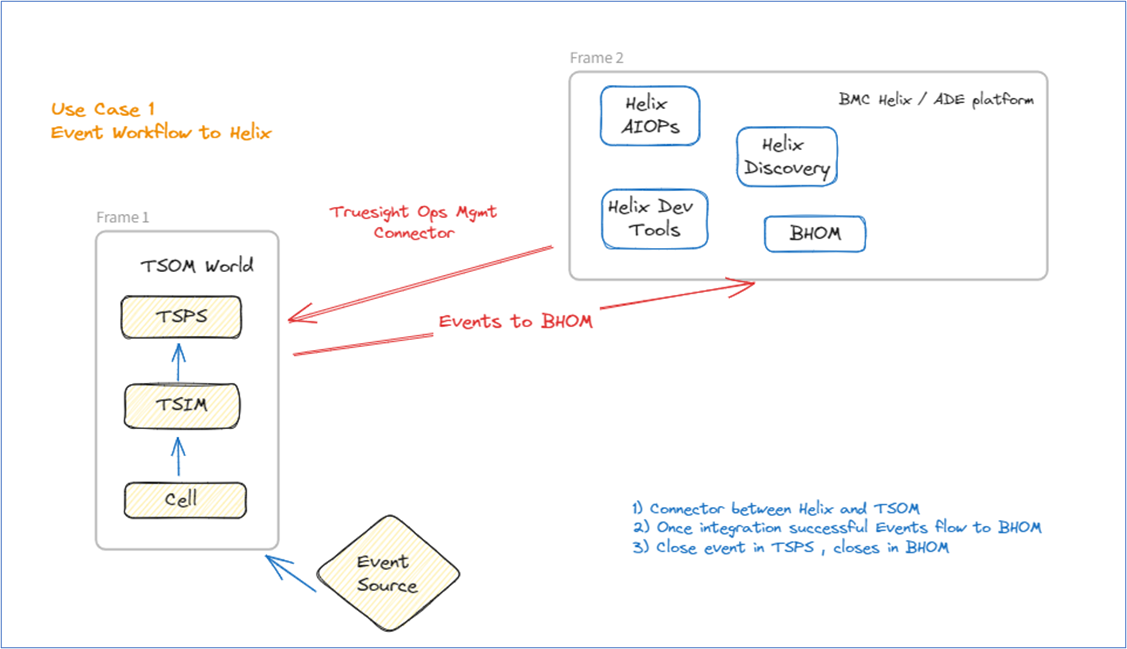
Figure 1. Use case 1 flow (TSPS is TrueSight Presentation Server, a component of TrueSight Operations Management).
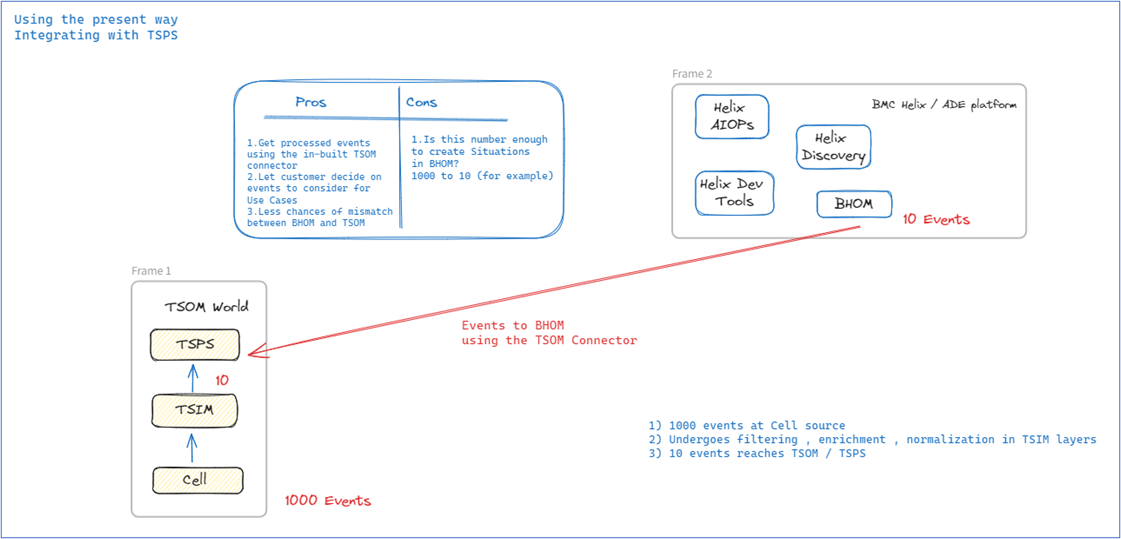
Figure 2. Use case 1 flow with pros and cons.
Use case 2—TrueSight Operations Management and BMC Helix Operations Management event data topology using BMC Helix Intelligent Integrations.
- Download, install, and configure the TrueSight Operation Management connector.
- Configuration Items (CIs) created manually in TrueSight Operation Management will get ingested into BMC Helix Operations Management.
- In BMC Helix Operations Management, we will observe the CIs getting ingested. In BMC Helix Discovery, we will see these CIs as generic elements.
- In BMC Helix Service Monitoring, we will not see these CIs as these are created manually in TrueSight Operations Management.
- Please note there is no back propagation, as of now, of event status from BMC Helix Operations Management to TrueSight Operations Management.
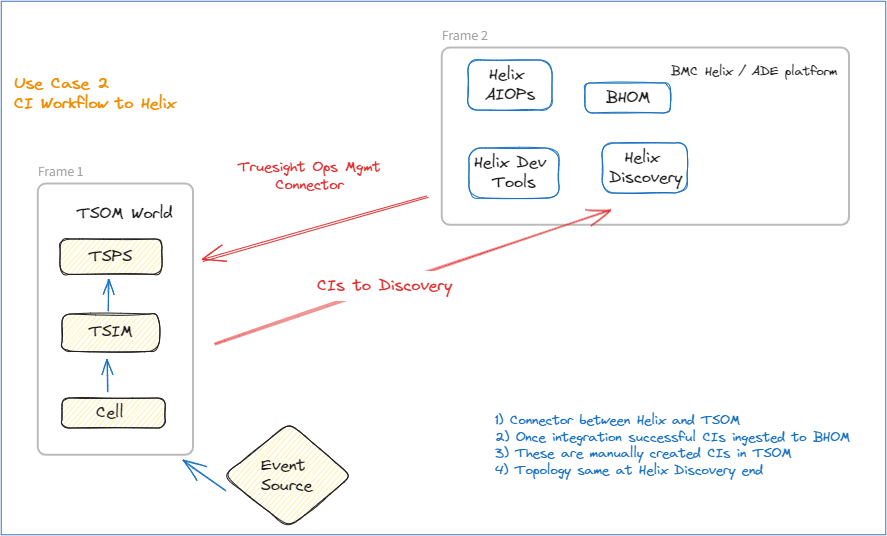
Figure 3: Use case 2 flow.
Use case 3—TrueSight Operations Management with a configuration management database (CMDB) and service models integrated into BMC Helix Operations Management topology using BMC Helix Intelligent Integrations
- Download, install, and configure the TrueSight Operation Management connector.
- This is like use case 2, the only difference here is the service models are created in the CMDB and published from the CMDB to TrueSight Operations Management.
- BMC Helix Discovery will show the same topology.
- In BMC Helix Service Monitoring (BMC Helix AIOps), we will see the business service models.
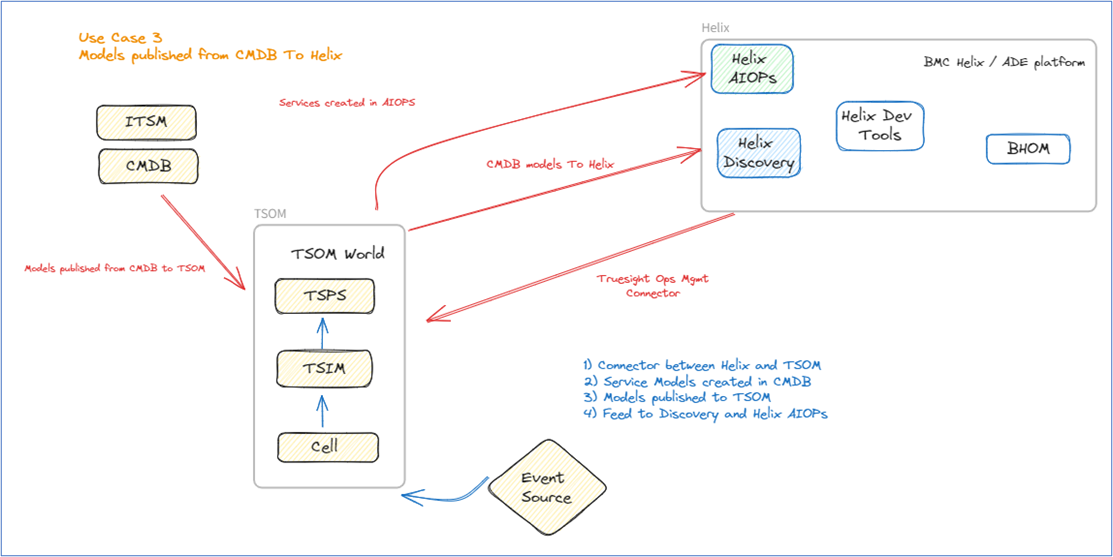
Figure 4. Use case 3 flow.
Use case 4—TrueSight Operations Management monitoring vCenter
- Add monitoring policy for vCenter KM in TrueSight Operations Management.
- vCenter hierarchy builds up in TrueSight Operations Management.
- We can see the vCenter CI in BMC Helix Discovery.
- We observe that the hierarchy does not have multilevel topology as in TrueSight Operations Management.
There is no use case diagram for this.
This completes the best practice steps you can use when trying to integrate TrueSight Operations Management with BMC Helix Service Monitoring (AIOps) using BMC Helix Intelligent Integrations.
For each of the four use cases, we have recorded a five-minute video demonstration, which can be obtained by request by emailing [email protected]
Conclusion
These use cases help IT teams that want to stay with TrueSight Operations Management while adopting BMC Helix Operations Management with AIOps and using BMC Helix Service Monitoring.
]]>Organizations often struggle to maintain seamless functionality and uninterrupted service delivery due to the overwhelming amount of data and events they face. This can lead to operational inefficiencies, prolonged downtime, and fragmented insights. Without a clear understanding of their IT infrastructure, businesses find themselves in a cycle of reactive firefighting. This lack of visibility not only hampers agility and innovation, but also leaves organizations vulnerable to costly disruptions and reputational damage.
In this type of landscape, the need for a comprehensive solution that ingests data while also synthesizing it into actionable intelligence becomes increasingly apparent. I would like to tell you about BMC Helix IT Operations Management (ITOM), a suite of software that goes beyond telemetry and event data to address your pain points head-on, empowering your IT to prevent incidents and delivering composite artificial intelligence (AI)-powered services (predictive, causal, and generative AI) for fast innovation.
Observability—Your key to reliable service delivery across complex IT systems
In a recent customer briefing, the topic of observability was discussed, along with the question of how BMC helps organizations solve the overwhelming amount of data and events. We shared a few key differentiators that demonstrate how BMC goes beyond processing telemetry and a short explanatory video.
There are many key features that BMC offers as part of BMC Helix ITOM, but I will highlight three here:
1. The FIRST key feature we’ll explore is dynamic service modeling (DSM), which revolutionizes how IT teams discover and manage services within their infrastructure. Through automated, real-time service modeling, BMC Helix ITOM ingests topology from BMC and third-party sources, identifying dependencies and relationships across the IT landscape, including infrastructure, applications, and software, to provide crucial visibility and context. By ensuring accuracy and consistency through automated reconciliation, this approach transforms the traditional methods, offering a comprehensive and dynamic understanding of the IT environment.
2. The SECOND key feature I’d like to highlight is root cause isolation. The business service is a complex and ephemeral graph of configuration items (CIs) and their relationships. Without the connected topology you get with DSM, and a business service to provide context for the domain, root cause isolation would not be possible.
Telemetry, events, and change requests are automatically mapped to the business service and impacted CIs. Causal AI is used to identify the root cause CI and correlate any impactful change requests. This eliminates the blame game when dealing with thousands of changes in the system.
3. The THIRD key feature I’ll highlight today is the BMC HelixGPT-powered best action recommendation (BAR) capability. BMC ITOM ingests textual data from telemetry, service management, and vulnerability systems, and ships a pre-trained large language model (LLM) with domain expertise.
The composite AI pipeline, based on predictions, impact, and root cause isolation, can then contextually ask BMC HelixGPT to summarize problem scenarios, surface log insights, and provide a BAR based on historical data.
As an example, imagine that you performed a code update, which resulted in increased CPU utilization that significantly strained host resources. A BAR can provide tailored recommendations by leveraging its pre-trained domain expertise and optionally fine-tuning it with customer data to address resource-related issues efficiently.
Achieving seamless functionality and uninterrupted service delivery is paramount. However, overwhelming data and events can lead to operational inefficiencies and prolonged downtime. With features like dynamic service modeling, root cause isolation, and best action recommendation, BMC Helix ITOM is the only fully integrated, open observability and AIOps solution with AI/ML-powered discovery, monitoring, optimization, automation, self-healing, and remediation of services, empowering IT to prevent incidents and innovate quickly. Click here to discover how BMC Helix ITOM can help you revolutionize your IT operations.
]]>BMC Helix AIOps and observability has been recognized as “Cross Infrastructure Analytics Solution of the Year” in the 5th annual Data Breakthrough Awards program conducted by Data Breakthrough, an independent market intelligence organization that recognizes the top companies, technologies and products in the global data technology market today.
“BMC Helix AIOps harnesses the latest innovations in AI to revolutionize cloud service delivery and operational visibility to generate insights across the entire application structure. Complex IT environments are challenging I&O teams to balance stability with speed and agility,” said Steve Johansson, Managing Director, Data Breakthrough. “BMC Helix AIOps has everything enterprises need for excellence in operations allowing users to understand system health, diagnose and fix problems faster and even predict and prevent potential issues before they occur. It truly transforms IT from reactive to proactive. Congratulations to the entire BMC team for their well-deserved 2024 Data Breakthrough Award win.”
The significance of this award, and what that means for your operations
As you know, your IT Operations teams face a difficult balancing act. With AI and ML at the forefront of driving efficiency and innovation, we designed the BMC Helix AIOps and observability to effectively utilize AI to increase the reliability of IT services and make IT more efficient. Our solution helps IT teams move out of firefighting mode, and we believe process-centric AIOps and observability represents the future of IT operations management, where traditional approaches are enhanced and augmented with AI-driven intelligence.
I’ll share with you the key features and benefits of BMC’s Helix AIOps and observability platform:
- Automation across Multi-Cloud and Hybrid Environments: These solutions automate operations processes and build accurate inventories of configuration items (CIs), aiding in efficiently managing IT resources.
- Dynamic Service Modeling: BMC Helix uses dynamic service models to integrate and normalize data, offering rich visualizations and a unified topology view across the entire underlying virtual and physical infrastructure, from application to network and cloud to mainframe.
- Service Blueprints: BMC Helix provides customizable service blueprints for defining and maintaining services, allowing organizations to model their IT services efficiently.
- AI and ML Application for Pattern Detection and Noise Reduction: By applying AI and ML, these solutions identify patterns, reduce operational noise, save time, and labor, and decrease the mean time to repair (MTTR).
- Predictive Analytics for Future Outcomes: The solutions predict future outcomes using historical data, aiding in strategic decision-making.
- Finding and Fixing Issues in Seconds: Our patented causal and generative AI algorithms rapidly diagnose and resolve issues using NLP and AI clustering. It streamlines incident management, enhancing IT efficiency and shifting focus from troubleshooting to strategic innovation.
- Proactive Issue Remediation and SLA Optimization: These technologies preemptively address issues, thus maintaining service level agreements, enhancing the customer experience, and reducing incident generation.
- Service-Centric Noise Reduction and Root Cause Analysis: The solutions effectively differentiate between critical and non-critical events, focusing on root cause analysis for efficient problem resolution.
- Advanced Anomaly Detection: Both univariate and multivariate anomaly detection services are provided, enabling early identification and remediation of potential issues.
- Service Outage Prediction: Utilizing ML techniques, these solutions predict service outages, allowing for proactive measures to maintain service quality.
- Real-Time Incident Correlation: Using advanced ML algorithms like BERT, the system automatically correlates incidents, enhancing the speed and accuracy of major incident management.
- Proactive Problem Management: The application of Kubernetes means clustering helps identify recurring incidents and streamline problem management.
Winning the prestigious title of “Cross Infrastructure Analytics Solution of the Year” in the Data Breakthrough Awards signifies more than just industry recognition. For you, it means entrusting your IT operations to a proven leader in the field, ensuring reliability, efficiency, and innovation at every step. With BMC Helix AIOps and observability, you can rest assured that you’re investing in a solution that has been rigorously evaluated and acknowledged for its excellence, ultimately translating into tangible benefits for your organization’s IT infrastructure.
The BMC Helix AIOps and observability platform represents a transformative approach to IT operations. Unlock your potential with our award-winning BMC Helix AIOps and observability platform today.
]]>